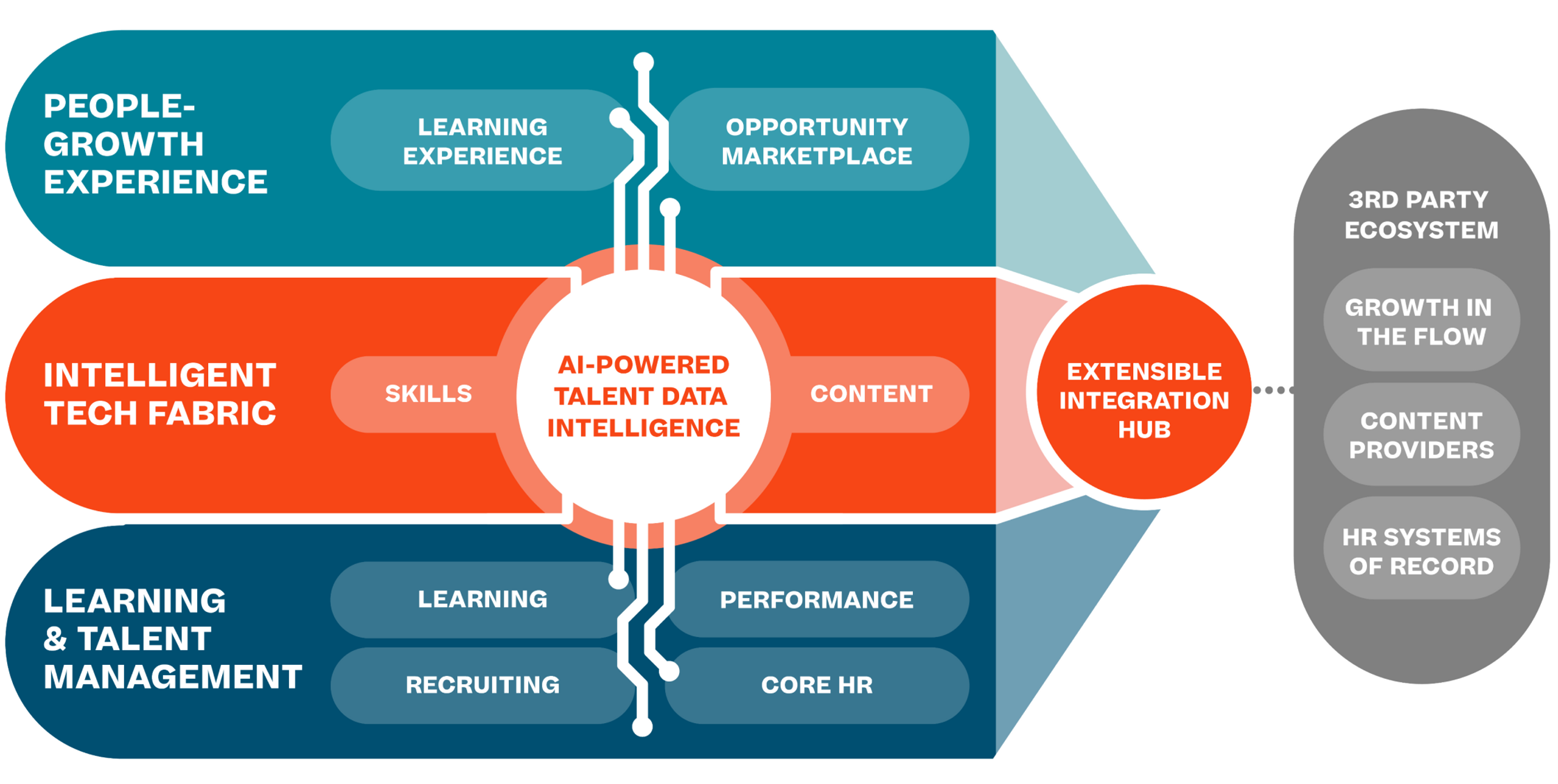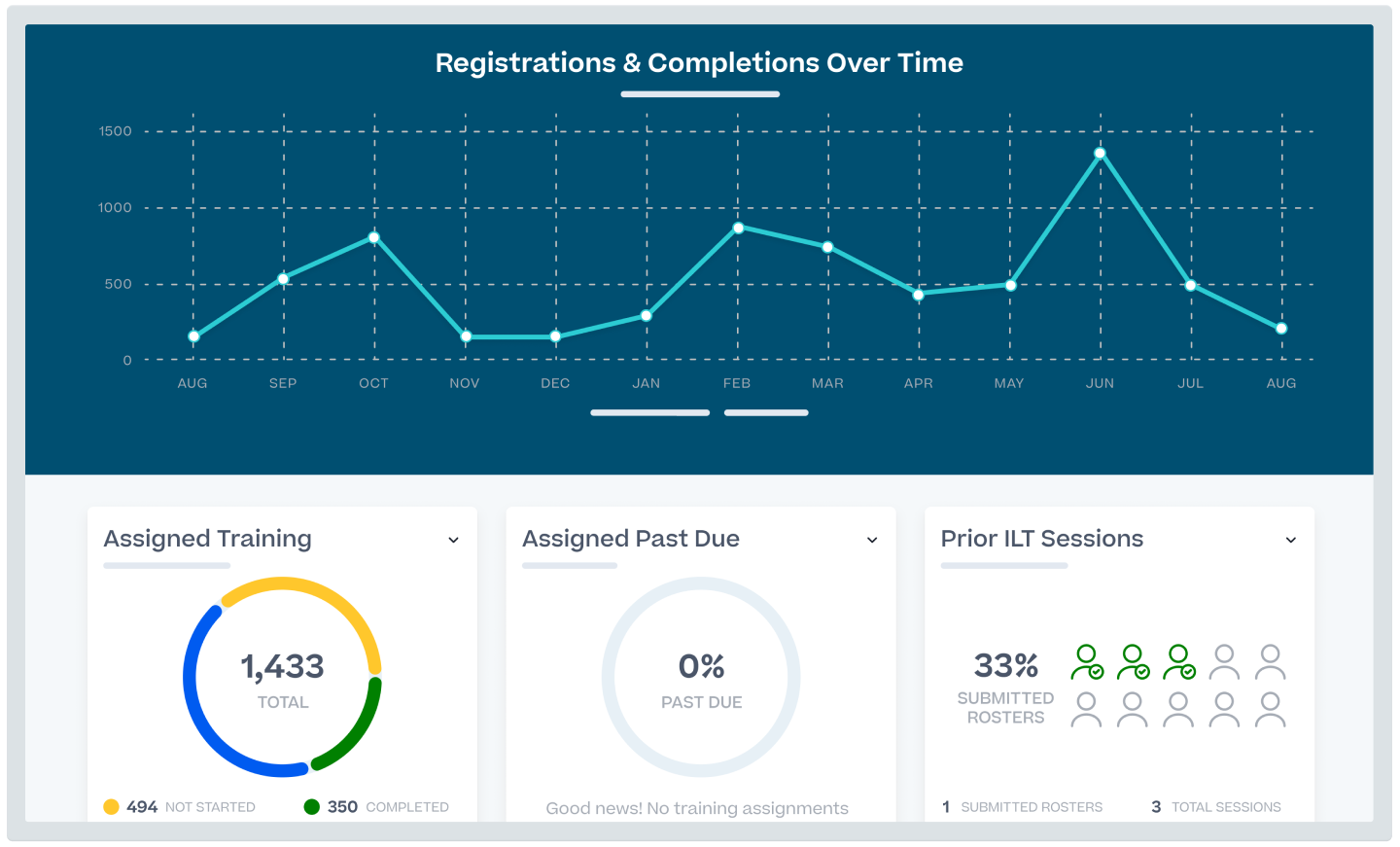







Consolidate to a single system for governing, assigning, automating, and tracking required training. With Cornerstone LMS, you can boost productivity with version management and seamless inline content workflows.

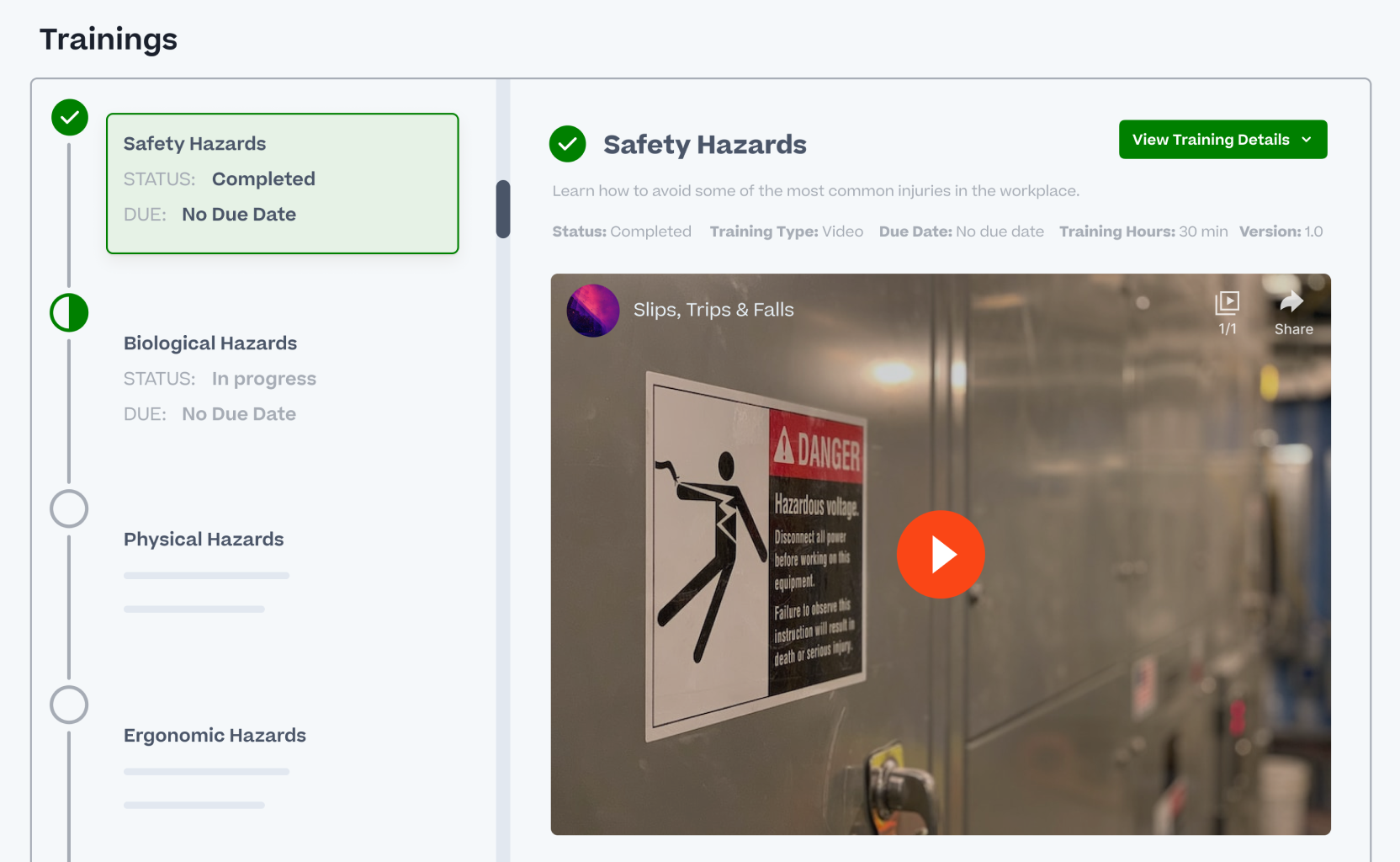
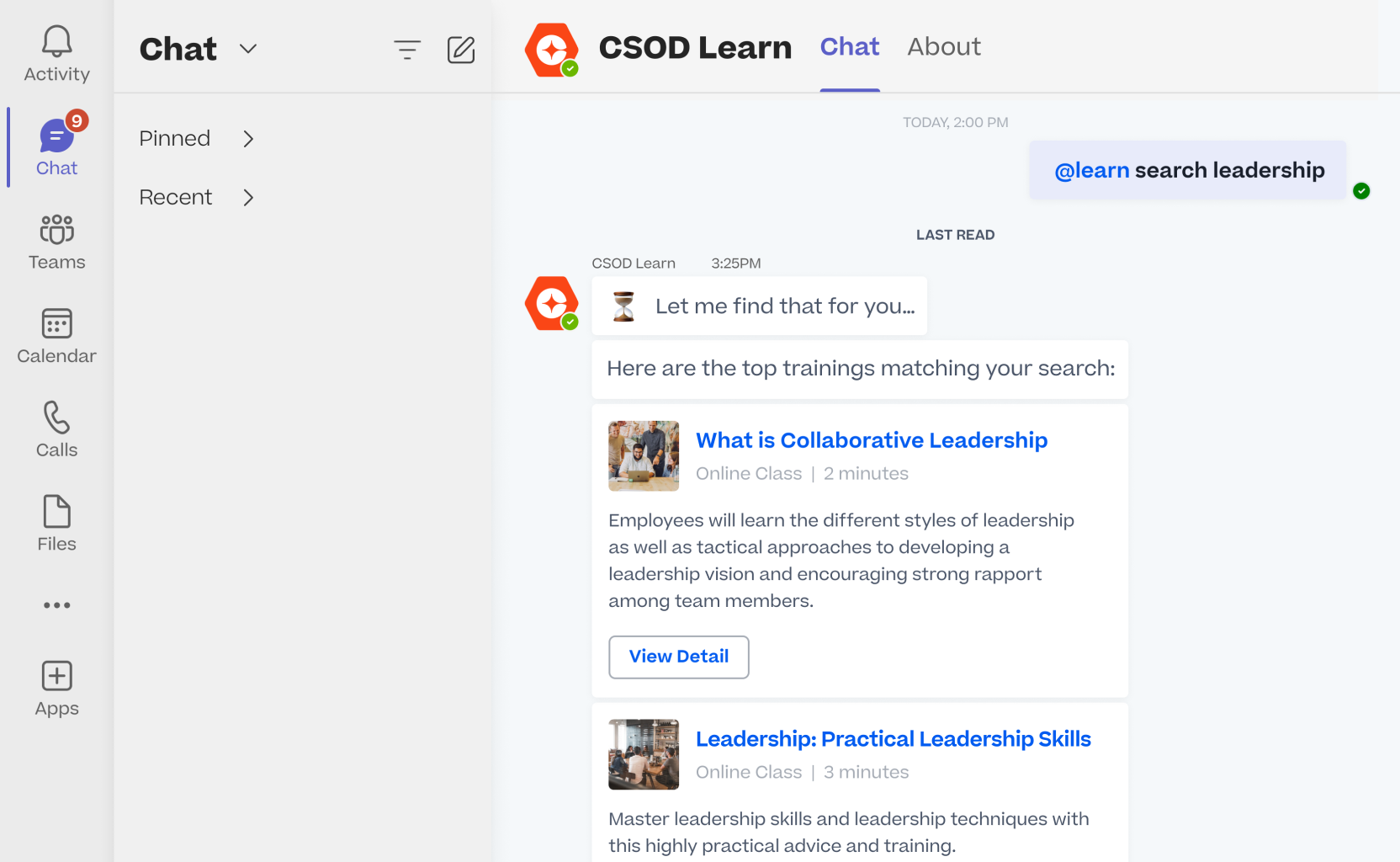
Empower your people to learn and collaborate anytime, anywhere, with the Cornerstone app and integrated enterprise and partner apps.
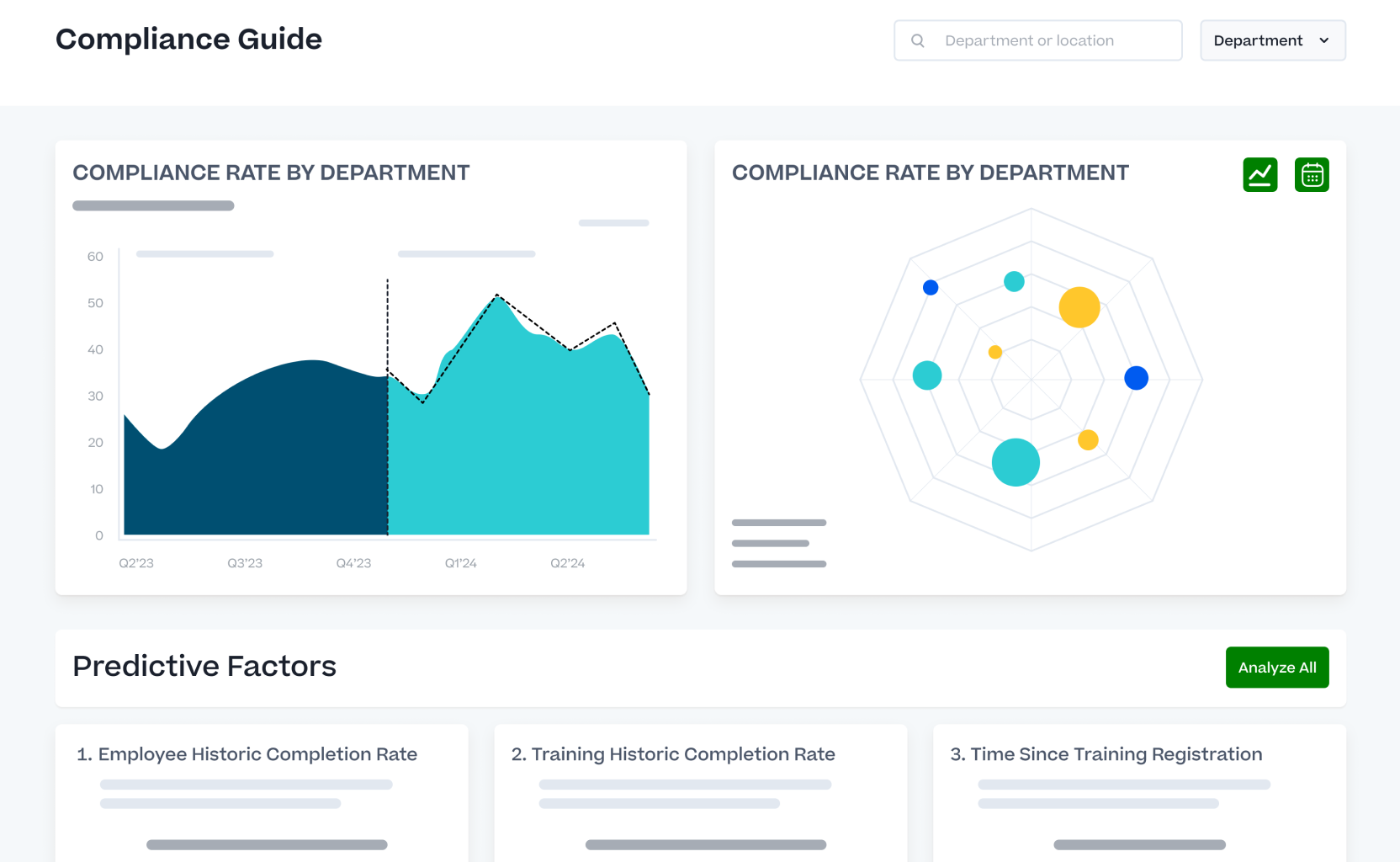
Automate your compliance learning workflows and provide insights around their effectiveness to better manage your continuous compliance training.